Raft算法中成员变更过程解析
备注:本文内容节选自《全面解读Raft共识算法》,想了解更全面的Raft算法解读,请移步链接即可。
在Raft论文中,成员变更属于难点,但这一部分相比于论文其他部分,确实讲解最不详细,让人读完之后很迷惑。
1、什么是成员变更?
成员变更指的是系统成员变化,即服务器节点的上下线,这和由于宕机故障导致的上下线是不同的。宕机或者重启导致的上下线,是不会影响系统的注册的成员数量的,也就不会影响到一致性判断所依据的“多数派”的生成,众所周知,“多数派”是所有一致性的基础。成员变更时,会修改注册的成员数量,比如在实际应用中,为了提高安全等级,就很可能出现需要把备机数量由三台扩充到五台,在这种情况下,就发生了成员变更。
另外,还有一个十分需要注意的地方:成员变更意味着大家都还活着,并不像宕机那样,立即死亡,无法再做“交接工作”。被变更的成员是需要完成“交接工作”的。所谓的“交接工作”,就是下文中提到的“做决策”。
2、直接变更存在的问题
在成员变更时,因为无法做到在同一个时刻使所有的节点从旧配置转换到新配置,那么直接从就配置向新配置切换就可能存在一个节点同时满足新旧配置的“超过半数”原则。
如下图,原集群由Server1、Server2、Server3,现在对集群做变更,增加Server4、Server5。如果采用直接从旧配置到新配置的切换,那么有一段时间存在两个不想交的“超过半数的集群”。
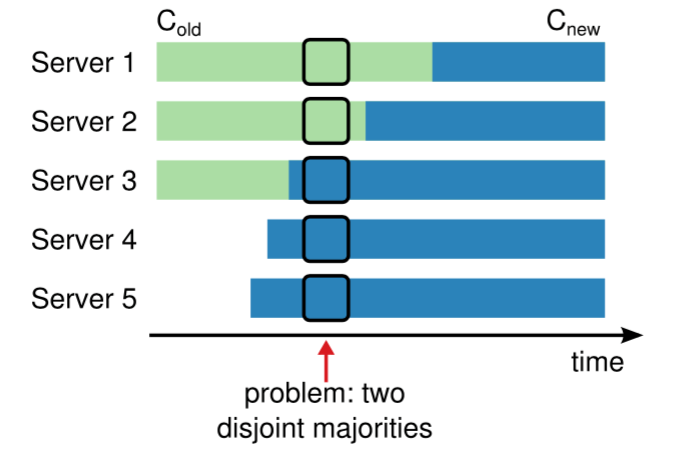
上图,中在中间位置Server1可以通过自身和Server2的选票成为Leader(满足旧配置下收到大多数选票的原则);Server3可以通过自身和Server4、Server5的选票成为Leader(满足新配置线,即集群有5个节点的情况下的收到大多数选票的原则);此时整个集群可能在同一任期中出现了两个Leader,这和协议是违背的。
3、Raft的成员变更实现方案:分阶段变更
Raft提出了通过一个中间过渡阶段,即联合共识(joint consensus),逐步把数据写入的新的集群中。其具体做法是2阶段提交式的:
第一阶段:Leader收到C-old到C-new的配置变更请求时,创建C-old-new的日志并开始复制给其他节点,此日志和普通日志复制没有区别。此时做决策的仍然是C-old集群。
第二阶段:当只有C-old-new复制到大多数节点后,Leader以这个配置做决定,这个时候处于一个共同决定的过程,因为此时做决策的是C-old-new集群。
由于两阶段变更不存在一个阶段C-old和C-new可以同时根据自己的配置做出决定,所以不会出现上文描述的情况。
备注:虽然自己是Leader,但是做决策的可不是Leader,它要根据多数派的原则进行拍板定方案,所以归根结底,做决策的还是集群中的其他Follower成员。
4、Raft论文解读
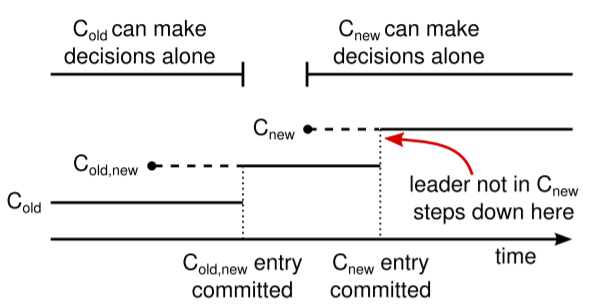
论文里面的这张图片看起来让人头大,个人感觉有点凌乱。虚线表示已创建但尚未提交的配置项,实线表示已经提交的配置项。最难以理解的地方在于最上面的“豁口”,其表示中间过渡阶段,即联合共识(joint consensus),其开始于C-old-new复制到大多数节点后,而结束于C-new提交之后,因为C-old-new与C-new的配置内容虽不相同但是一致,两者是等价的,所以可以视为C-new能够单独做决定。当C-new被复制到大多数节点的时候,如果Leader不在C-new之内,则自己做下线处理,C-new集群开始进行新的选主操作。