
Linux入门教程
备注1:本系列Linux入门教程总共有30小节,当前已经更新12小节,最后更新日期为:2021年6月26日,未完待续...。
备注2:互联网上很多的东西都太零散太随意,碰到问题上网寻求解决,还算尚可,但是要想寻找好的教程还是非常困难的,因为很多内容都是新手写的,有经验的老手没有时间写或者不想写,所以导致大家学习Linux的过程中,总是云里雾里,终不能提升真正的Linux技术能力。而本系列教程的目的就是解决当前中国IT环境的现状问题,收集了网上很多高质量的内容,并根据站长北侠的真实经验,汇集而成。
备注3:本系列教程为Linux入门教程,请先思考一下,学到什么程度才算是Linux入门呢?一千个读者有一千个哈姆雷特,但是只有一个莎士比亚。所以说,Linux入门的标准肯定是统一的,不会因人而异。北侠认为,只有深刻理解inode才算是对Linux入了门。如何才算是深刻理解inode呢?请看下面的两个思考题。
备注4:阅读本系列教程之前,请先思考两个问题:(1)inode的ID来自何处?(2)inode与文件描述符fd有什么关系?如果这两个问题能回答出来,那么本系列教程可以不看,否则请认真阅读本系列教程。inode是Linux操作系统的重心,深刻理解并掌握inode才算是Linux入门,否则连门都没有入。
前言
本系列教程的内部代号为“趣味Linux”,由北侠编写,特供于站长徒弟,先拿出一部分进行公开,其中绝大部分内容属于个人原创,也有少数部分内容来源于互联网修订而来。恕北侠直言,网上很多菜鸟类的Linux入门教程,纯粹是一堆冷冰冰的文字的堆积,自称为“教程”,真是辱没了“教程”两字。
Linux难学吗?其实并不难,难的是没有好的入门教程。因为一份好的教程,十分难得,不仅需要作者数年的经验沉淀,更需要对相关知识的深刻把握和悟性思考,这样才能把知识点学活、写活,才能做出一份高质量的教程,从而让广大读者受益。可是,在中国当下的环境来看,初学者众多,浮躁心更甚,35岁的技术宿命论,所以缺少产出高质量教程的沃土环境。本系列教程希望能做到抛砖引玉,引领更多更高质量的IT技术教程。
本系列教程分为几大模块,每个模块由若干小结构成。技术之所以有趣,并不是因为它可以通过漫画的形式呈现出来。其实,北侠很反感那些把技术做成漫画的微信公众号作者,纯粹是为了吸引眼球而漫画。因为不同的内容应该有不同的表现形式,都统一搞成漫画的形式,岂不是犯了一根筋的毛病,犯了教条主义错误?在北侠看来,技术之所以有趣在于知识点之间会有令人想不到的联系。例如:Unix <---> Linux <---> GUN(角马) <---> GPL相互联系;再例如:inode <---> 文件描述符 <---> 数组索引相互联系;再例如:空格 <---> 命令参数间隔 <---> shell数组元素间隔相互联系等等。
至于说为什么Linux技术点的背后会有这么多的底层联系?因为任何事物都是发展和成长的,最初由一个小点,从而扩展成一个体,所以点与点之间存在各种联系。举例来说,为了标识文件所以造出inode这个东西,但是不同的进程读写文件的偏移量的不同的,所以又造出一个文件描述符这么一个东西,所以inode和文件描述符就存在非常强的联系。抓住这些联系,才能将知识串联起来,才能将知识学活,才能真正的体会到技术的有趣。
最后,想说的一点是,本系列教程总共有30章节,北侠将陆续公布在MyBatis中文网上。欢迎大家的关注!另外,为了照顾手机端的用户,本系列教程可以在APP端进行学习,请大家前往各大应用商店下载“北侠云计算联盟”APP。
| 第一部分:开源社区的江湖恩怨 |
|---|
| 第一节:三国鼎立,江湖恩怨 |
| 第二节:理想社会:GNU组织 |
| 第三节:统一战线:POSIX |
| 第四节:Shell的重生历史 |
| 第二部分:磁盘与文件系统 |
|---|
| 第一节:一切皆即是文件 |
| 第二节:Linux基本组成部分 |
| 第三节:硬盘的基础知识(扇区、磁道、柱面) |
| 第四节:磁盘块与扇区的区别和联系 |
| 第五节:Linux系统中软连接和硬链接 |
| 第六节:Linux的inode的深度理解 |
| 第七节:Linux的时空隧道:目录 |
| 第八节:磁盘与文件系统 |
| 第三部分:Linux用户管理 |
|---|
| 第一节:Linux个性化设置:环境变量 |
第一节:三国鼎立,江湖恩怨
有人的地方,既有江湖,必分门派。不仅人类的社会发展进程如此,科技的发展皆是如此。
在西方极乐世界,先后涌现出三大帮派。
第一个帮派是Unix,这是由一群科学家建立的。科学家思想单纯,一门心思搞科研,然后转换成果来变现,所以Unix是一个商业化的产品。
第二大帮派是GNU,其老大精力充沛,充满理想主义色彩,只因为看不惯唯利是图的Unix,就想创建一套完全自由、免费的操作系统。这个老大采用的战略是:农村包围城市。在老大的带领下,此帮派开发了很多周边的产品,比如功能强大的文字编辑器Emacs,再如性能强悍的C语言编译器GCC等等,但是老大时运不济,一直打游击战,从没有占领过核心城市,自始至终都没有做出自己的操作系统,甚是可惜啊。
第三大帮派是Linux内核,这个门派的老大性格孤僻,但是眼光独到,只做内核,做的风生水起。树大了自然会开枝散叶,引起百鸟前来筑巢,GNU组织的大量自由软件都纷纷过来占位,门庭如市,车水马龙,好不热闹。
一年又一年过去了,GNU的操作系统一直没有做出来,而自己的手下和门徒都跑Linux内核组织了,GNU门派的老大有点坐不住了,黑着脸找上门,告诉Linux内核的老大,以后不能再叫“Linux”,应该叫“GNU/Linux”,毕竟拿人手短,Linux内核组织的老大也不好说什么。不过,世人的习惯难改啊,有的叫Linux,有人称GNU/Linux,一直这么延续着,反正都是一回事。
第二节:理想社会:GNU组织
1、GUN组织
计算机软件作为人类的知识财富,为人类社会的发展起到了巨大的作用,但长期以来软件源码作为个人或公司的私有财产受到严格的保密,很难做到像文学艺术作品一样地进行公开的交流,很大程度上造成软件的低水平,重复劳动严重,在一定意义上制约了软件的发展。
1985 年由 MIT 教授理查德·斯托曼(Richard Stallman)提出应将软件源码看成人类共同拥有的知识财富,应该公开地自由交换、修改,随后提出了 GNU 计划,并建立了自由软件基金会。同时,他还发布了一份举足轻重的法律文件---GNU 通用公共授权书(GNU GPL, GNU General Public License),对日后软件业的发展启动了极大的推导和规范作用。
2、GPL协议
GNU是一个技术组织,发起人是 Richard Stallman。在这个组织里面黑客云集、高手如林,其作品多是编译器、语法分析器等惊世骇俗之大作。这个组织的成员不仅技术过人,思想修为也远胜他人,他们的理念就是:软件源码看成人类共同拥有的知识财富,应该公开地自由交换、修改,成为“自由软件”。
基于造福人类的高尚思想,GNU组织公布了GPL协议。GPL 协议的核心就是要对源码进行公开,并且允许任何人修改源码,但是只要使用了 GPL 协议的软件源码,其衍生软件也必须公开源码,准许其他人阅读和修改源码,即 GPL 协议具有继承性。另外,需要注意的是:GPL 软件并非就是免费软件,这里所说的“自由软件”是指对软件源码的自由获得与自由使用、修改,软件开发者不但可以通过服务来收费,而且还可以通过出售 GPL 软件来获利。至此,在 GPL 下人们就可以自由交流、修改软件源码了,这一协议极大地推动了整个计算机软件行业的发展。
3、GNU是GNU Not Unix的递归缩写,前面那个G是什么意思?
有网友发出疑问:
GNU是GNU Not Unix的递归缩写,前面那个G是什么意思?为什么不是 ANU, BNU, CNU...
递归首字缩写,是一种在全称中递归引用它自己的缩写。如此命名的还有很多,包括:Bing is not google,PNG is Not GIF.....,这在计算机领域黑客社区中一个较早的传统,特别是在麻省理工大学,黑客们喜欢使用幽默地引用自身或其他缩写的缩写。
GNU = GNU's Not Unix,引用自身则表示G的意思是"GNU这个系统本身",即G是GNU的缩写('s可忽略)。那问题就变成了怎么选中GNU这个单词来作为命名的。
许多递归缩写包括否定语,通常用来指出这个缩写指代的事物 a 不是与另一个事物 b 相类似(但事实上,这个事物 a 通常与 b 非常相似甚至是 b 的衍生品)。
命名的这些人要开发的是一个类似Unix又不是Unix的东西,想延续传统使用递归缩写来命名,然后包括否定语的递归缩写的常见命名格式有两种:
[A-Z]IN[A-Z] =>"[A-Z]IN[A-Z] is Not [a-zA-Z]+"
[A-Z]N[A-Z] => "[A-Z]N[A-Z]'s Not [a-zA-Z]+"。已知末尾的[a-zA-Z]+ = Unix ,替换一下就是 "[A-Z]INU is Not Unix" 或 "[A-Z]NU's Not Unix"。
最后就是填字游戏了,把*INU/*NU中的"*"替换成26个英文字母中的一个,要求能凑成一个单词且这个单词最好是个名词,选来选去也就Gnu这个单词最合适,Gnu还有公牛的意思,既满足命名规则还能当logo,一举两得。

第三节:统一战线:POSIX
POSIX,全称是:Portable Operating System Interface of Unix,中文含义是:可移植操作系统接口。POSIX标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称。
1、中间人:操作系统
程序员编写程序,操作计算机硬件,例如打开摄像头或者打印Word,你以为是程序直接操作硬件(摄像头或打印机)吗?错,非也,而是这样的流程:程序->操作系统->硬件,操作系统是中间人,而且是必不可少的中间人。
程序对硬件的所有操作都是通过中间人-操作系统来完成的。操作系统专门定制了应用程序接口 API(Application Programming Interface)供程序来使用。
由于Unix操作系统的衍生版本很多,为了实现“一次编写,到处运行”的宏伟目标,所以人们提出了“可移植操作系统接口”这个伟大的规划。
POSIX是可移植操作系统接口(Portable Operating System Interface)的首字母缩写。POSIX是基于UNIX的,这一标准意在期望获得源代码级的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统上编译执行。
2、操作系统接口
什么是操作系统的接口呢?接口其实是一种抽象,比如插线板,它将内部的电路全部封装起来,只提供外露的插口,用电设备插上即用,不必关心插座内部是如何实现的。操作系统的接口也是如此,操作系统的接口其实就是一个个函数,知道它的功能然后直接调用就行,而不用管操作系统内核里面是怎么实现的。

操作系统向编程人员提供了“程序与操作系统的接口”,简称程序接口,又称应用程序接口 API(Application Programming Interface)。该接口是为程序员在编程时使用的,系统和应用程序通过这个接口,可在执行中访问系统中的资源和取得操作系统的服务,它也是程序能取得操作系统服务的唯一途径。大多数操作系统的程序接口是由一组系统调用(system call)组成,每一个系统调用都是一个能完成特定功能的子程序。
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境来使应用程序具有更好的兼容性,为了达到这个目的,内核提供一系列具备预定功能的多内核函数,通过一组称为系统调用(system call)的接口呈现给用户。系统调用把应用程序的请求传给内核,调用相应的内核函数完成所需的处理,将处理结果返回给应用程序。
3、POSIX在Windows和Linux上的用武之地
POSIX(Portable Operating System Interface of Unix),POSIX标准定义了操作系统应该为应用程序提供的接口标准,目的是为了增强程序的可移植性。主流的操作系统有两种,一种是Windows系统,另一种是Linux系统。由于操作系统的不同,API又分为Windows API和Linux API。在Windows平台开发出来的软件在Linux上无法运行,在Linux上开发的软件在Windows上又无法运行,这就导致了软件移植困难,POSIX(Protabl Operation System 可移植操作系统规范)应运而生。
完成同一功能,不同内核提供的系统调用(实现某功能的函数)是不同的。例如,创建进程,Linux下是fork函数,Windows下是creatprocess函数。如果用户现在在Linux下写一个程序,用到fork函数,那么这个程序该如何往Windows上移植?是否需要把源代码里的fork通通改成creatprocess,然后重新编译...?POSIX标准的出现就是为了解决这个问题。Linux和Windows都要实现基本的POSIX标准,Linux把fork函数封装成posix_fork,Windows把creatprocess函数也封装成posix_fork,都声明在unistd.h里。这样,程序员编写普通应用时候,只用包含unistd.h,调用posix_fork函数,程序就在源代码级别可移植了。
第四节:Shell的重生历史
很多人对Shell的认识是片面的,看下面一名知乎网友的疑问:
最近想学学 Linux 下的 Shell,基础知识都看完了,想做点东西,但是绞尽脑汁还是没想起来做点什么,最后我也查了一下 Shell 的作用,到现在还没有一个很好的答案,都说 Shell 可以直接与计算机交互,但是我想其他语言不也能方便的与计算机进行交互吗?Shell 实现的功能,其他语言也能实现,可能会稍微复杂一些,难道 Shell 就这点优势吗?望解惑!感激不尽。
从这个问题就能看出来,题主对Shell的定位没有理解。题主不应该拿Shell跟其他语言来对比,更不应该有这样的质疑:Shell 实现的功能,其他语言也能实现,可能会稍微复杂一些,难道 Shell 就这点优势吗?
关于Shell的定位,应该从它的名字说起,操作系统分为内核(kernel)和外壳(shell)。也就是说Shell的定位属于操作系统。题主拿操作系统的东西去跟编程语言去对比,明显不对等,门不当户不对啊。
操作系统的作用是什么呢?是管理计算机硬件与软件资源的计算机程序。那么Shell的作用也是如此,即是管理计算机硬件与软件资源。
正如题主所说,“最近想学学 Linux 下的 Shell,基础知识都看完了,想做点东西,但是绞尽脑汁还是没想起来做点什么”。因为我们平时很少会去管理计算机硬件和软件的,所以题主找不到Shell的用武之地,这很正常。
Shell是用来管理计算机硬件与软件资源的,所以Shell就像一个胶水,能粘合其他的各种语言,实现软件资源的配合和协作。
1、Shell 门派之争
Linux 中的 shell 有很多类型,其中最常用的几种是:Bourne shell (sh)、C shell (csh) 和 Korn shell (ksh),它们各有优缺点,用户则萝卜青菜,各有所爱。
2、Bourne Shell 出师不利

Bash:Bourne again shell
Bourne shell 是 Unix 最初使用的 shell,并且在每种 Unix 上都可以使用,虽然它在编程方面相当优秀,但在处理与用户的交互方面做得不如其他几种shell。
说到底,shell这个物种,不仅要功能强大,而且还需要容易上手,毕竟shell是“人-机”交互的接口,不同于其他的编程语言,它们侧重于后台批处理任务,与人的交互不是首要考虑的问题。而shell要做到“通机器,懂人性”,这样才能有更多的受众人群。
3、sh的重生之路
后来,创始人 Bourne 决定赋予 Bourne shell 新的生命,使其更适合于交互式使用,因此开创了新的项目并命名为 “Bourne again shell”,简称 “Bash”,也有好事者称 Bash 为 “重生shell(born again shell)”。
Bash 是 Bourne shell 的扩展,与 Bourne shell 完全向后兼容,并且在Bourne shell 的基础上增加和增强了很多特性。可以提供如命令补全、命令编辑和命令历史表等功能,它还包含了很多 C shell 和 Korn shell 中的优点,有灵活和强大的编程接口,同时又有很友好的用户界面。所以,Linux 操作系统缺省的 shell 是 Bash。
4、得民心得天下
要想赢得用户占领市场就得有抓住人们的内心需求,得民心者得天下,这个道理在shell上如此,在python shell领域同样又上演了一次,python自带的shell功能不强大,交互性不强,从而给了ipython shell上位的机会。后来ipython shell越做越大,直至发展成ipython notebooks。
notebooks是文本化编程思想的体现,文档和代码交错在一起,文档给人写的,代码给电脑运行。
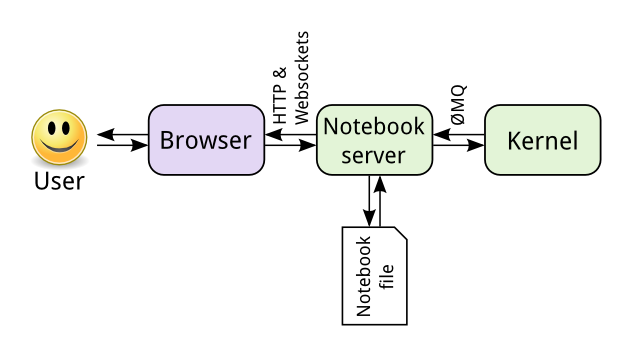
从交互命令行编程发展到文本化编程,这是思想上巨大的提升。后来,ipython notebooks改名为jupyter notebooks,从此之后一路绝尘,成为一个大名鼎鼎的科学利器。如果说有什么每个数据科学家都应该使用或必须了解的工具,那非jupyter notebooks莫属了。
5、后记
除了bash以外,国外的大神都喜欢用自己的名字来给软件起名,例如,下面的这些大神的名字都与软件绑定到一起了:
(1)Linux 因其发明者 Linus Torvalds 的名字命名的;
(2)Debian Linux 是其创始人 Ian Murdock 和 他当时的女友 Debra Lynn 的名字的混成词;
(3)awk 代表着 Aho、Weinberger、Kernighan三位作者;
补充:
另外,在Windows系统下还有PowerShell。PowerShell从Windows7开始已经内置于Windows操作系统中。PowerShell可以看作是cmd的升级版,可以对应用程序进行自动化管理,功能比cmd强大的多。PowerShell是基于.NET环境的管理工具。
第一节:一切皆即是文件
Linux,全称GNU/Linux,是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。伴随着互联网的发展,Linux得到了来自全世界软件爱好者、组织、公司的支持。
在Linux之下,一切皆文件。在Linux操作系统中,可以将一切都看作是文件,包括普通文件,目录文件,字符设备文件(如键盘,鼠标...),块设备文件(如硬盘,光驱...),套接字等等,所有一切均抽象成文件,提供了统一的接口,方便应用程序调用。
1、inode节点
就像进程用PID来描述和定位一样,在Linux系统中,文件使用inode节点来描述。inode 是对文件的索引。例如一个文件系统,所有文件是放在磁盘之上,就要编个目录来说明每个文件在什么地方,有什么属性,以及大小如何等。inode节点就像书本的目录一样,便于查找和管理。
2、文件描述符
在Linux中,内核通过inode来找到每个文件,但一个文件可以被许多用户同时打开或一个用户同时打开多次。这就有一个问题,如何管理文件的当前位移量,因为可能每个用户打开文件后进行的操作都不一样,这样文件位移量也不同,当然还有其他的一些问题。所以Linux又搞了一个文件描述符(file descriptor)这个东西,来分别为每一个用户服务。每个用户每次打开一个文件,就产生一个文件描述符,多次打开就产生多个文件描述符,一一对应,不管是同一个用户,还是多个用户。该文件描述符就记录了当前打开的文件的偏移量等数据。所以一个inode节点可以有0个或多个文件描述符。多个文件描述符可以对应一个inode节点。
3、文件描述符的取值范围
由于文件描述符包含了文件的操作状态,例如文件位移量等,所以用户程序都有自己的文件描述符表,调用open 打开一个文件的时候,内核分配一个文件描述符并返回给用户程序,用户程序就存入自己的文件描述符表,然后使用文件描述符表的索引 (即0、1、2、3等数字)来标识文件,这些索引就称为文件描述符(File Descriptor),用int 型变量保存。
操作系统为每一个进程维护了一个文件描述符表,该表的索引值都从从0开始的,所以在不同的进程中可以看到相同的文件描述符,这种情况下相同的文件描述符可能指向同一个文件,也可能指向不同的文件,具体情况需要具体分析。
当一个应用程序刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。如果此时去打开一个新的文件,它的文件描述符会是3。POSIX标准要求每次打开文件时(含socket)必须使用当前进程中最小可用的文件描述符号。
文件描述符是一个重要的系统资源,理论上系统内存多大就应该可以打开多少个文件描述符,但是实际情况是,内核会有系统级限制,以及用户级限制,目的是不让某一个应用程序进程消耗掉所有的文件资源,可以使用ulimit -n 查看。
4、文件描述符与inode的关系
应用程序进程拿到的文件描述符,即进程文件描述符表的索引,通过索引拿到文件指针,指向系统级文件描述符表的文件偏移量,再通过文件偏移量找到inode指针,最终对应到真实的文件。
第二节:Linux基本组成部分
Linux系统一般有4个主要部分:内核、Shell、文件系统和应用程序。内核、Shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。
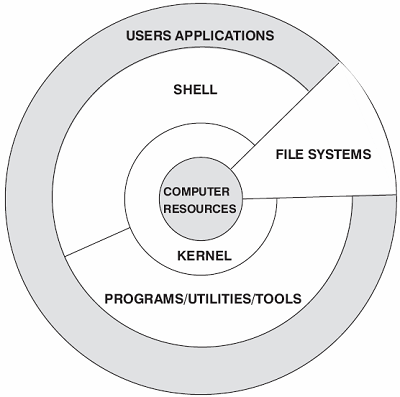
1、Linux内核
内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
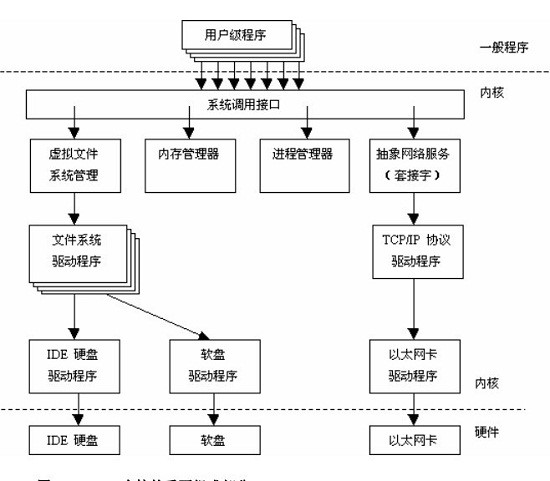
Linux 内核由如下几部分组成:内存管理、进程管理、设备驱动程序、文件系统和网络管理等。如图:
2、Linux Shell
Shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行,是一个命令解释器。另外,Shell编程语言具有普通编程语言的很多特点,用这种编程语言编写的shell程序与其他应用程序具有同样的效果。目前主要有下列版本的shell。
1、Bourne Shell:是贝尔实验室开发的。
2、BASH:是GNU的Bourne Again Shell,是GNU操作系统上默认的shell,大部分linux的发行套件使用的都是这种shell。
3、Korn Shell:是对Bourne SHell的发展,在大部分内容上与Bourne Shell兼容。
4、C Shell:是SUN公司Shell的BSD版本。
3、Linux 文件系统
文件系统是文件存放在磁盘等存储设备上的组织方法。Linux系统能支持多种目前流行的文件系统,如EXT2、 EXT3、 FAT、 FAT32、 VFAT和ISO9660。
Linux下面的文件类型主要有:
1) 普通文件:C语言元代码、SHELL脚本、二进制的可执行文件等。分为纯文本和二进制。
2) 目录文件:目录,存储文件的唯一地方。
3) 链接文件:指向同一个文件或目录的的文件。
4) 设备文件:与系统外设相关的,通常在/dev下面。分为块设备和字符设备。
5)管道(FIFO)文件: 提供进程之间通信的一种方式
6)套接字(socket) 文件: 该文件类型与网络通信有关
可以通过ls –l, file, stat几个命令来查看文件的类型等相关信息。
4、Linux 应用
标准的Linux系统一般都有一套都有称为应用程序的程序集,它包括文本编辑器、编程语言、X Window、办公套件、Internet工具和数据库等。
5、Linux内核参数优化
内核参数是用户和系统内核之间交互的一个接口,通过这个接口,用户可以在系统运行的同时动态更新内核配置,而这些内核参数是通过Linux Proc文件系统存在的。因此,可以通过调整Proc文件系统达到优化Linux性能的目的。
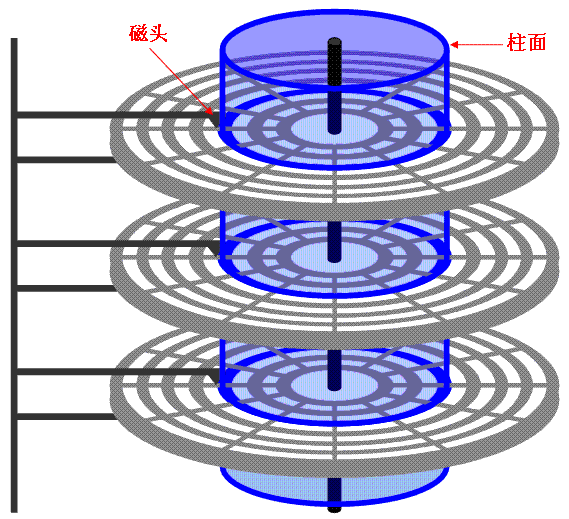
第三节:硬盘的基础知识(扇区、磁道、柱面)
1、盘片
硬盘中一般会有多个盘片组成,每个盘片包含两个面,每个盘面都对应地有一个读/写磁头。受到硬盘整体体积和生产成本的限制,盘片数量都受到限制,一般都在5片以内。盘片的编号自下向上从0开始,如最下边的盘片有0面和1面,再上一个盘片就编号为2面和3面。如下图:
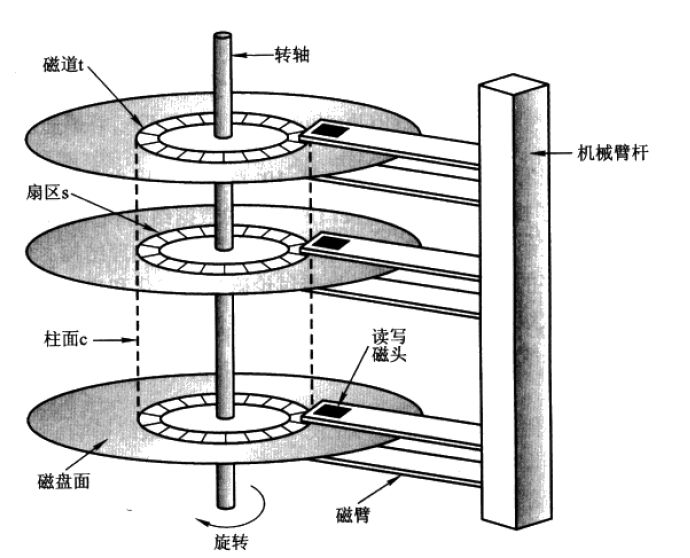
2、扇区和磁道
下图显示的是一个盘面,盘面中一圈圈灰色同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分为若干个弧段,每个磁道上一个弧段被称之为一个扇区(图践绿色部分)。扇区是磁盘的最小组成单元,通常是512字节。
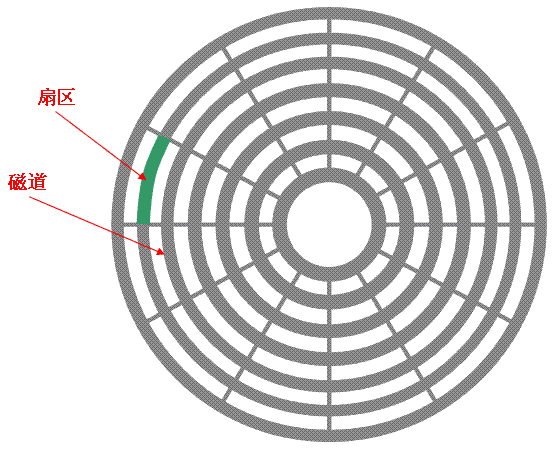
备注:由于不断提高磁盘的大小,部分厂商设定每个扇区的大小是4096字节
3、磁头和柱面
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。 如下图
第四节:磁盘块与扇区的区别和联系
1、什么是扇区?
下图显示的是一个盘面,盘面中一圈圈灰色同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分为若干个弧段,每个磁道上一个弧段被称之为一个扇区(图践绿色部分)。扇区是磁盘的最小组成单元,通常是512字节。
2、什么是磁盘块?
操作系统与磁盘之间交流的最小单位就是磁盘块,它是一个虚拟的概念。是对于操作系统(软件)来说有意义的概念。
由于扇区的数量比较小,数目众多在寻址时比较困难,所以操作系统就将相邻的扇区组合在一起,形成一个块,再对块进行整体的操作。
操作系统忽略对底层物理存储结构的设计。通过虚拟出来磁盘块的概念,在系统中认为块是最小的单位。
3、磁盘的读写基本单位是什么?
读写基本单位是扇区。磁盘的原理,物理实现,磁盘控制器是按照扇区这个单位读取等操作数据的。此题问磁盘的读写,和操作系统没有关系,千万不要联系到操作系统层面去了。
磁盘块与扇区的大小关系
既然磁盘块是一个虚拟概念。是操作系统自己"杜撰"的。软件的概念,不是真实的。所以大小由操作系统决定,操作系统可以配置一个块多大。一个块大小=一个扇区大小*2的n次方。N是可以修改的。
4、块与页的关系
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单位。所以,与内存操作,是虚拟一个页的概念来作为最小单位。与硬盘打交道,就是以块为最小单位。
第五节:Linux系统中软连接和硬链接
在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号inode 。
1、软连接
软连接,其实就是新建立一个文件,这个文件专门用来指向别的文件,类似于 Windows 下的快捷方式。
软链接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用。cat那个软链接文件,则提示“没有该文件或目录”。
补充:软连接类似于pyvenv.cfg文件
学过Python的小朋友,应该见过虚拟环境中的pyvenv.cfg吧。Python虚拟环境可以为项目创建相互独立的开发环境。既然是虚拟环境的配置文件,那么必定包括主环境的存放地址,就是下面的 home 目录,还得包括是否从主目录拷贝第三方库文件等,其内容如下所示:
home = D:\Python37
include-system-site-packages = true
version = 3.7.12、硬连接
硬连接是不会建立inode的,它只是在文件原来的inode link count域再增加1而已,也因此硬链接是不可以跨越文件系统的。相反,软连接会重新建立一个inode,当然inode的结构跟其他的不一样,它只是一个指明源文件的字符串信息。一旦删除源文件,那么软连接将变得毫无意义。而硬链接删除的时候,系统调用会检查inode link count的数值,如果大于等于1,那么inode不会被回收,因此文件的内容不会被删除。
硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件。可以通过ls -i来查看一下,这两个文件的inode号是同一个,说明它们是同一个文件;而软链接建立的是一个指向文件,即链接文件内的内容是指向原文件的指针,它们是两个文件。
3、软连接和硬连接的区别
(1)软链接可以跨文件系统,硬链接不可以;
(2)软链接可以对一个不存在的文件名(filename)进行链接(当然此时如果你vim这个软链接文件,linux会自动新建一个文件名为filename的文件),硬链接不可以(其文件必须存在,inode必须存在);
(3)软链接可以对目录进行连接,硬链接不可以。
(4)两种链接都可以通过命令 ln 来创建。ln 默认创建的是硬链接,使用 -s 开关可以创建软链接。
第六节:Linux的inode的深度理解
必读提醒:阅读下文之前,请先搞明白inode和文件描述符的关系
在Linux中,内核通过inode来找到每个文件,但一个文件可以被许多用户同时打开或一个用户同时打开多次。这就有一个问题,如何管理文件的当前位移量,因为可能每个用户打开文件后进行的操作都不一样,这样文件位移量也不同,当然还有其他的一些问题。所以Linux又搞了一个文件描述符(file descriptor)这个东西,来分别为每一个用户服务。每个用户每次打开一个文件,就产生一个文件描述符,多次打开就产生多个文件描述符,一一对应,不管是同一个用户,还是多个用户。该文件描述符就记录了当前打开的文件的偏移量等数据。所以一个inode节点可以有0个或多个文件描述符。多个文件描述符可以对应一个inode节点。摘录于 第一节:一切皆即是文件
1、block 和 inode 概述
在Linux系统中,文件由元数据(inode)和数据块(block)组成。数据块就是多个连续性的扇区(sector),扇区是文件存储的最小单位(每个512字节)。数据块的大小,最常见的是4KB,也就是连续8个sector组成,其存储文件数据和目录数据。而元数据用来记录文件的创建者、创建日期、文件大小等信息,元数据又被称为“索引节点”。
元数据具体包含的信息有inode号,文件的字节数、User ID、Group ID、读、写、执行权限、时间戳(共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间)、链接数(软硬链接)、数据block的位置。需要注意的是:元数据里面没有文件名。因为它里面存储都是人眼看不见的东西。
在硬盘格式化的时候,操作系统就会将硬盘分为两个区,即元数据区和数据区。每个元数据节点的大小一般为128B或者256B,元数据的总数在格式化文件系统的时候就已经确定。当系统存在大量小文件的时候,虽然文件的数据不大,但是文件数量巨多,导致元数据个数也是急剧膨胀,由于元数据也是占有一定的存储空间,所以也会极大的消耗硬盘空间,最终导致即便硬盘空间很大,也往往不能再存储新的文件。
2、inode的存储内容
可以用stat命令,查看某个文件的inode信息:
# stat example.txt
[root@root ~]# stat example.txt
File: ‘example.txt’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd01h/64769d Inode: 132584 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-01-21 12:12:47.993332596 +0800
Modify: 2021-01-21 12:12:47.993332596 +0800
Change: 2021-01-21 12:12:47.993332596 +0800
Birth: -3、inode的大小和总数
硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
[root@root ~]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda1 2621440 88262 2533178 4% /
devtmpfs 482897 327 482570 1% /dev
tmpfs 485240 1 485239 1% /dev/shm
tmpfs 485240 451 484789 1% /run
tmpfs 485240 16 485224 1% /sys/fs/cgroup
tmpfs 485240 1 485239 1% /run/user/0由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
4、文件的inode号和文件名
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。需要注意的是:Unix/Linux系统内部不使用文件名而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上来看,用户通过文件名,打开文件。实际上,操作系统内部将这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
ls命令只列出目录文件中的所有文件名,ls -i命令列出整个目录文件,即文件名和inode号码。使用ls -i命令,可以看到文件名对应的inode号码:
[root@root ~]# ls -i example.txt
132584 example.txt6、硬链接与inode
一般情况下,文件名和inode号码是一一对应关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内,对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
ln命令可以创建硬链接:ln 源文件 目标文件
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:".“和”…"。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录)。
补充:软链接
除了硬链接以外,还有一种特殊情况:文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:“No such file or directory”。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。ln -s命令可以创建软链接:ln -s 源文文件或目录 目标文件或目录
7、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
(1)有时文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。在日常工作中总会碰到这样的情况,难以删除或者管理某些文件,因为这些文件的文件名中使用了短横线或者其他特殊字符或者其文件名完全不正确。这很可能是有人对该文件进行了错误命名。因为 Linux 中的大多数命令,包括开关或者选项在内,都是以连字符 (-) 或者双连字符 (--) 开头的,很难使用诸如 rm、mv 和 cp 之类常用的命令来操作这些文件,如下所示:
# ls
- -- -p fileA fileB fileC fileD幸运的是,某些命令提供了一些选项,以用来显示相关文件所关联的 inode 的索引编号。ls 命令就提供了一个这样的选项:
(2)方便软件更新。打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。此点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
北侠发问:在Linux系统中文件名有什么特点呢?
参考答案:
(1)打开一个文件以后,Linux操作系统就以inode号码来识别这个文件,不再考虑文件名,此时可以直接对文件进行替换,而在Window操作系统中,往往会以“文件被占用”而拒绝执行操作。
(2)在软连接中,文件A的内容是文件B的文件名。
(3)inode里面没有文件名。文件名属于数据块的内容。
北侠发问2:inode号是从哪来的呢?
请自行思考,如果实在得不到答案,请联系北侠。
第七节:Linux的时空隧道:目录
备注:此文风看似荒诞,但是,在逻辑世界里,在想象时空中,这并不荒诞,因为技术就是源于想象,想象就是脱离现实就是荒诞。
在Windows操作系统中,先将硬盘分区,然后再在分区上建立目录。所以,在Windows操作系统中,所有路径都是从分区的盘符开始,如下所示:
C:\Program Files\Oracle
D:\Program Files\Tencent而Linux操作系统正好相反,是先虚拟出一个根目录,再将硬盘挂载到根目录中。在Linux操作系统中所有路径都是从根目录开始:
先规划出一个根目录/,然后来了一块硬盘A,它就可以挂载到根目录下;然后再过来一块硬盘B,它只能挂载在到根目录/的子目录下,例如/b。如果在过来一块硬盘C,它可以挂载到/b/c下。
至此,已经有三个目录:/、/b、/b/c,从逻辑角度上来看,b和c都是/的子目录,而且c是b的子目录,但从物理角度来看,/、/b、/b/c分布属于不同的硬盘,进入/根目录,犹如进入一个时空隧道,可以不断的穿越:
一个人想串门,首先进入了根目录/来到了硬盘A的世界,然后他拐歪儿进入了/b目录,此时进入了磁盘B的世界,他在/b目录里面游荡,怎么玩都没事,但是一旦他进入/b/c目录里面,就进入了磁盘C世界。
目录是磁盘的时空隧道,可以自由穿梭于不同的磁盘之间。如何得知自己处于哪个磁盘之上呢,以及磁盘占用的情况呢?此时,可以通过磁盘的命令:df -h,可以得知其挂载的目录是什么,以及磁盘占用的情况。
另外,如果要想查看目录占用磁盘空间的大小是多少呢?请使用命令:du -h /dirname。
备注:参数
-h:显示磁盘/目录的大小,以人性化的形式。
第八节:磁盘与文件系统
1、磁盘分区是什么?
计算机中存放信息的主要的存储设备就是硬盘,但是硬盘不能直接使用,必须对硬盘进行分割,分割成的一块一块的硬盘区域就是磁盘分区。在传统的磁盘管理中,将一个硬盘分为两大类分区:主分区和扩展分区。主分区是能够安装操作系统,能够进行计算机启动的分区,这样的分区可以直接格式化,然后安装系统,直接存放文件。除去主分区所占用的容量以外,硬盘剩下的容量就被认定为扩展分区(也就是说:一块硬盘除去主分区外的容量后,如果对剩下的容量进行了再分区,那么,这个再分区就是扩展分区)。扩展分区是不能直接使用的,他是以逻辑分区的方式来使用的,所以说扩展分区可以分成若干个逻辑分区。他们的关系是包含的关系,所有的逻辑分区都是扩展分区的一部分。扩展分区如果不再进行分区了,那么整个扩展分区就是逻辑分区了。
任何硬盘在使用前都要进行分区。硬盘的分区有两种类型:主分区和扩展分区。一个硬盘上最多只能有4个主分区,其中一个主分区可以用一个扩展分区来替换。也就是说主分区可以有1~4个,扩展分区可以有0-1个,而扩展分区中可以划分出诺干个逻辑分区。
2、磁盘表示方案
目前常用的硬盘主要有两大类:IDE接口硬盘和SCSI接口硬盘。IDE接口的硬盘读写速度比较慢,但价格相对便宜,家用PC常用的硬盘类型。SCSI接口的硬盘读写速度比较快,但价格相对较贵。通常,要求较高的服务器会采用SCSI接口的硬盘,一台计算机一般有两个IDE接口(IDE0和IDE1),每个IDE接口上可连接两个硬盘设备(主盘和从盘)。采用SCSI接口的计算机也遵循这一规律。
Linux的所有设备均表示为/dev目录中的一个文件,如:
IDE0接口上的主盘称为/dev/had,IDE0接口上的从盘称为/dev/hdb。
SCSI0接口上的主盘称为/dev/sda,SCSI0接口上的从盘称为/dev/sdb
由此可知,/dev目录下“hd”打头的设备是IDE硬盘,“sd”打头的设备是SCSI硬盘。设备名称中的第三个字母为a,表示为第一个硬盘,而b表示为第二个硬盘,并依此类推。分区则使用数字来表示,数字1~4用于表示主分区或扩展分区,逻辑分区的编号从5开始。IDE0接口上主盘的第一个主分区称为/dev/hda1,IDE0接口上主盘的第一个逻辑分区称为/dev/hda5
3、Ext2和Ext3文件系统
北侠提醒:如果您对上文中的inode有深刻理解的话,那么阅读本节内容将会有种醍醐灌顶之感觉,否则阅读此内容真是云山雾罩,白费时间。
Ext2和Ext3是Linux操作系统常用的文件系统,Ext2/Ext3文件系统使用索引节点(即inode节点)来记录文件信息,作用像Windows的文件分配表。索引节点是一个结构,它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号。Linux文件系统将文件索引节点号和文件名同时保存在某数据结构中。所以,此数据结构只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。 对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问它。
Linux缺省情况下使用的文件系统为Ext2,Ext2文件系统的确高效稳定。但是,随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来了:其中系统缺省使用的Ext2文件系统是非日志文件系统,这在关键行业的应用是一个致命的弱点。
Ext3文件系统是直接从Ext2文件系统发展而来,Ext3文件系统已经非常稳定可靠。它完全兼容Ext2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是Ext3日志文件系统初始设计的初衷。
Ext2与Ext3的区别如下:
(1)Ext2和Ext3的格式完全相同,只是在Ext3硬盘最后面有一部分空间用来存放Journal(日志)的记录;
(2)在Ext2中,写资料到硬盘中时,先将资料写入缓存中,当缓存写满时才会写入硬盘中;
(3)在Ext3中,写资料到硬盘中时,先将资料写入缓存中,鼗缓存写满时系统先通知Journal,再将资料写入硬盘,完成后再通知Journal,资料已完成写入工作;
(4)是否有Journal的差别:
在Ext2中,系统开机时会去检查有效位(Valid bit),如果值为1,表示系统上次有正常关机;如果为0,表示上次关机未正常关机,那系统就会从头检查硬盘中的资料,这样时间会很长;在Ext3中,也就是有Journal机制里,系统开机时检查Journal的资料,来查看是否有错误产生,这样就快了很多。
第一节:Linux个性化设置:环境变量
如果你使用 macOS 或者Linux 的话,你会发现有很多的隐藏文件。尤其是 bash 相关的隐藏文件,更是让你眼花缭乱。

1 .bashrc 文件介绍
.bashrc 文件主要保存个人的一些个性化设置,最常见的用处是设置命令别名。
文件名中的 "rc" 是出自 "run commands"。最初的源头是麻省理工学院在 1965 年发展的 CTSS 系统,其中有一个从档案中取出一系列命令来执行的功能,其被称为 run commands,这种档案又称为一个 runcom。至此疑惑顿开,.bashrc 就是这种类型的文档,用于存放命令的别名貌似合情合理。
通常情况下,.bashrc 文件的内容为:
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# 加载全局设置
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi2 .bash_profile 文件介绍
.bash_profile 文件的侧重点是 "profile",跟环境有关,常用于设置环境变量。
window 里面的环境变量分为:系统变量和用户变量。home 下的 bash_profile 就是存放用户变量的地方。
.bash_profile 文件内容如下所示:
# 获取定义的别名
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# 设置环境变量
PATH=$PATH:$HOME/bin
export PATH3 .bash_history 文件介绍
.bash_history 文件记录用户使用过的命令