Raft 日志复制
1、Raft 日志的基本内容
Raft日志包含三块基本内容:
(1)索引号:整数,用于标识日志所在的位置
(2)任期号:创建该日志时Leader所处的当前任期号
(3)可以被复制状态机执行的命令
日志由有序编号(log index)的日志条目组成。每个日志条目包含:日志被创建时的任期号(term)和用于状态机执行的命令。如下图所示,
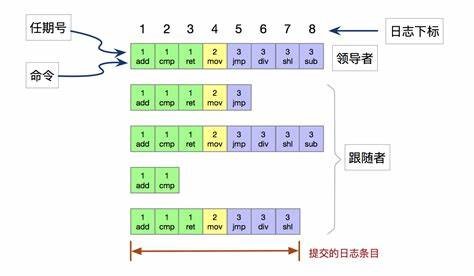
上图显示,共有 8 条日志,提交了 7 条。提交的日志都将通过状态机持久化到磁盘中,防止宕机。
2、Raft 日志复制的过程
Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行地向Follower发起 AppendEntries RPC 复制日志条目请求。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。如果Follower宕机或者运行缓慢或者丢包,Leader会不断的重试,直到所有的Follower最终都复制了所有的日志条目。
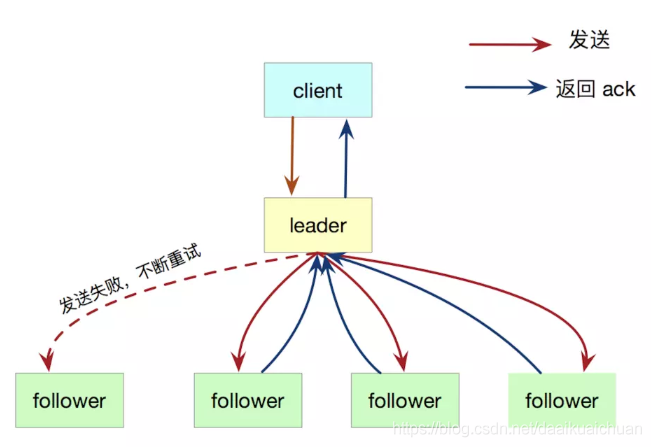
3、Raft 日志的一致性检查
如上所述,Follower在接收到AppendEntries RPC消息后则会返回复制成功的回复。实际上在接收到消息后会首先进行日志的一致性检查(正常情况下Leader与Follower的日志会保持一致,所以一致性检查不会失败),一致性检查内容如下:
在Leader创建AppendEntries RPC消息时,消息中将会包含当前日志之前日志条目的任期号与索引号。Follower在接受到AppendEntries RPC消息后,将会检查之前日志的任期号与索引号是否匹配到。如果匹配则说明和Leader之前的日志是保持一致的,否则,会拒绝AppendEntries RPC消息。
4、Raft 日志不一致的解决方案
4.1、日志不一致的三种情况
网络不可能一直处于正常情况,因为Leader或者某个Follower有可能会崩溃,从而导致日志不能一直保持一致,因此存在以下三种情况:
(1)Follower缺失当前Leader上存在的日志条目。
(2)Follower存在当前Leader不存在的日志条目。比如,旧的Leader仅仅将AppendEntries RPC消息发送到一部分Follower就崩溃掉,然后新当选Leader的服务器恰好是没有收到该AppendEntries RPC消息的服务器。
(3)Follower即缺失当前Leader上存在的日志条目,也存在当前Leader不存在的日志条目。
为了更好的说明这三种情况,请看下面的图示。
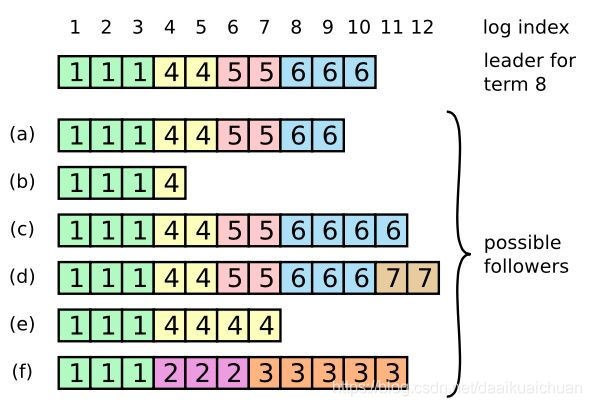
备注:
(1)图中最上方是日志的索引号(1-12),每个方块代表一条日志信息,方块内数字代表该日志所处的任期号。
(2)图中当前Leader(图中最上方一行日志代表当前Leader日志)处于任期号为8的时刻。
下面,以此图分析说明以上三种情况存在的原因:
(1)Follower a、Follower b满足以上说明的第一种情况:Follower崩溃没有接收到Leader发送的AppendEntries RPC消息。
(2)Follower c在任期为6的时刻,Follower d在任期为7的时刻为Leader,但没有完全完成日志的发送便崩溃了,满足以上说明的第二种情况:Follower存在当前Leader不存在的日志条目。
(3)Follower e在任期为4的时刻,Follower f在任期为2、3的时刻为Leader,但没有完全完成日志的发送便崩溃了,同时在其他服务器当选Leader时刻也没有接收到新的Leader发送的AppendEntries RPC消息,满足第三种情况:Follower即缺失当前Leader上存在的日志条目,也存在当前Leader不存在的日志条目。
备注: 如上文所示,根据日志的任期数目来判断节点是否为Leader,再次印证了任期的关键作用。
4.2、日志不一致的解决方案
Leader通过强迫Follower的日志重复自己的日志来处理不一致之处,这意味着Follower日志中的冲突日志将被Leader日志中的条目覆盖。这个过程如下所示:
首先,Leader找到与Follower最开始日志发生冲突的位置,然后删除掉Follower上所有与Leader发生冲突的日志,最后将自己的日志发送给Follower以解决冲突。需要注意的是:Leader不会删除或覆盖自己本地的日志条目。
当发生日志冲突时,Follower将会拒绝由Leader发送的AppendEntries RPC消息,并返回一个响应消息告知Leader日志发生了冲突。
Leader为每一个Follower维护一个nextIndex值。该值用于确定需要发送给该Follower的下一条日志的位置索引。该值在当前服务器成功当选Leader后会重置为本地日志的最后一条索引号+1。
当Leader了解到日志发生冲突之后,便递减nextIndex值,并重新发送AppendEntries RPC到该Follower,不断重复这个过程,一直到Follower接受该消息。
一旦Follower接受了AppendEntries RPC消息,Leader则根据nextIndex值可以确定发生冲突的位置,从而强迫Follower的日志重复自己的日志以解决冲突问题。
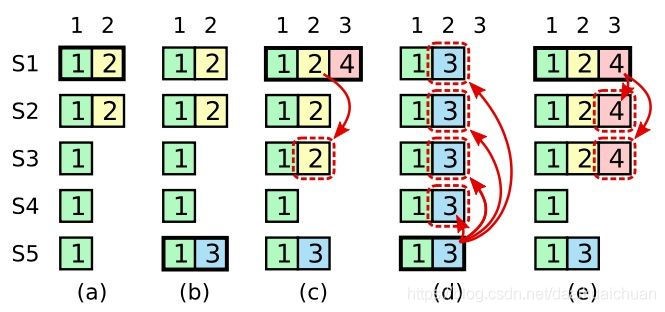
情况a:如上图,服务器S1在任期为2的时刻仅将日志<index:2,term:2>发送到了服务器S2便崩溃掉。
情况b:服务器S5在任期为3的时刻当选Leader(S5的计时器率先超时,递增任期号为3,高于服务器S3和S4,因此可以当选Leader),但没来得及发送日志便崩溃掉。
情况c:服务器S1在任期为4的时刻再次当选Leader(S1重启时,任期仍然为2,收到新的Leader S5发送的心跳信息后更新任期为3,而在Leader S5崩溃后,服务器S1为第一个计时器超时的,因此发起投票,任期更新为4,大于网络中其他服务器任期,成功当选Leader),同时将日志<index:2,term:2>发送到了服务器S2和S3,但还没有通知服务器对日志进行提交便崩溃掉。
情况d:情况(a->d)如果在任期为2时服务器S1作为Leader崩溃掉,S5在任期为3的时刻当选Leader,由于日志<index:2,term:2>还没有被复制到大部分服务器上,并没有被提交,所以S5可以通过自己的日志<index:2,term:3>覆盖掉日志<index:2,term:2>。
情况e:情况(a->e)如果在任期为2时服务器S1作为Leader,并将<index:2,term:2>发送到S2和S3,成功复制到大多数成员服务器上。S1成功提交了该日志,那么即便S1崩溃掉,S5也无法成功当选Leader,因为S5不具备网络中最新的已被提交的日志条目,S5只有term为1的日志。