Raft 日志的作用
Raft是目前著名的分布式共识算法,它分为四大功能模块:
- 领导者选举
- 日志同步、心跳
- 持久化
- 日志压缩,快照
这四个模块彼此并不完全独立,如日志的同步情况左右着领导者选举,心态是日志同步的特例,持久化和快照又都是围绕着日志的存储展开。可以说,Raft的核心就是日志,掌握好日志的方方面面是学好Raft共识算法的重要条件。
心跳机制
领导者与追随者之间的日志同步有一种特殊情况:Entries为空,即无日志同步。既然没有日志需要发送,那么为什么要发送AppendEntries请求了?
因为领导者需要宣示自己的权利,如果领导者不发送请求,那么追随者会认为领导者「死亡」了,会自发的进行下一轮选举,霸道的领导者肯定不愿意这种情况发生,因此即使日志是空的,也要发送AppendEntries请求,这种特殊的场景被称为「心跳」。
备注:"请求"一词用的不妥,应该理解成命令或者指令,以显示leader的支配和领导权利。
日志的作用
Raft集群中的节点通过日志来保存数据,且日志是只可追加的(Append-only),如下图所示:
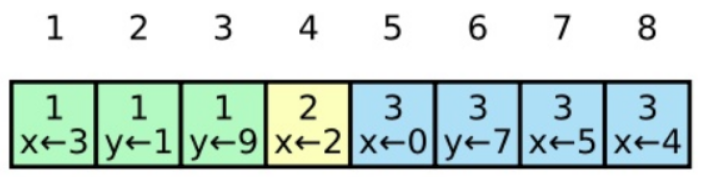
日志已提交与已应用的区别
日志分为两种状态:已提交和已应用。两者有什么区别了?
已提交表示日志已经追加到日志文件中了,已应用表示已经将日志应用到状态机上了。
已提交的日志被应用后才会生效,数据的可见性是由状态机来保证的。Raft使用了状态机来保证相同日志被应用不同节点后,数据是一致的。如下图所示:
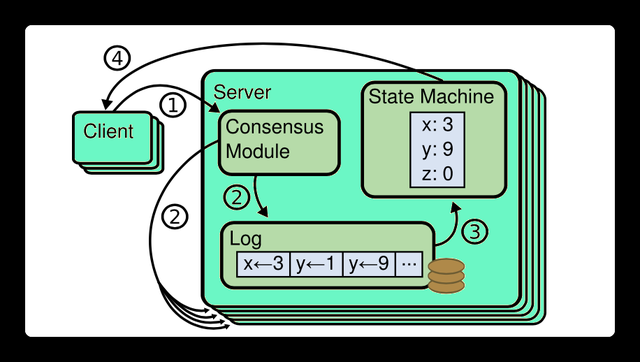
状态机保证了不同节点在被应用了相同日志后,数据的可见性是一致的,这样就能保证集群数据的一致性,这也是Raft算法的根本目的所在。
领导者选举
请求者在发送RequestVote请求时,会附带上自己日志的最后序号和任期,回复者接收到这两条信息后,会将其与自己的任期和日志进行比较,来看看双方谁的日志比较完整。首先比较任期,任期大的更有话语权,如果任期相同,再比较日志序号。当请求者比当前节点的日子更完整,当前节点才能投出选票。
但请求者的日志序号大或者相等,那么upToDate为true,只有当upToDate为true 时,
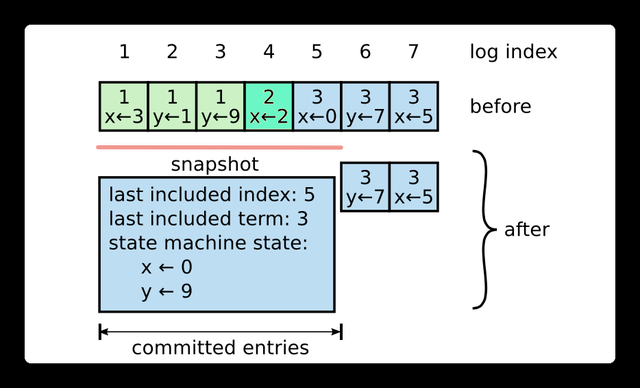
日志快照
节点是无法容忍日志数据无限增加的。为了解决这个问题,Raft引入了快照机制,如下图: